
یادگیری ماشین در Rapidminer
یادگیری ماشینی در Rapidminer بر اساس الگوریتمهایی عمل میکند که رایانهها را قادر میسازد الگوهایی را در دادهها پیدا کنند و آنها را به رفتار بهینه تبدیل کنند. الگوریتمهای یادگیری ماشین از تکنیکهای محاسباتی برای «یادگیری» اطلاعات مستقیماً از دادهها بدون تکیه بر یک معادله از پیش تعیینشده به عنوان مدل استفاده میکنند.
برای هر کسب و کاری بسیار مهم است که شاخص «نیروی کار» را در بازههای زمانی مشخص ارزیابی کند. این به شما امکان می دهد پروژه های تجاری را که همیشه عمدتاً بر اساس منابع انسانی است، برنامه ریزی کنید.
یکی از عوامل خطر ممکن است فوران فصلی سرماخوردگی باشد، زمانی که هر سال در زمستان تعداد قابل توجهی از کارمندان در مرخصی استعلاجی هستند. در نتیجه، ضربالاجلهای پروژه تغییر میکند و هر شرکتی مطمئناً دوست دارد از چنین تغییراتی اجتناب کند. یادگیری ماشینی می تواند به این امر کمک کند.
با کمک RapidMiner دادههای مربوط به سرماخوردگی را تجزیه و تحلیل میکنیم و مدلی میسازیم که بتواند شیوع بیماری را پیشبینی کند. بر اساس نتایج پیش بینی، شرکت قادر خواهد بود اقداماتی را از قبل انجام دهد و از زیان جلوگیری کند.
داده کاوی در رپیدماینر
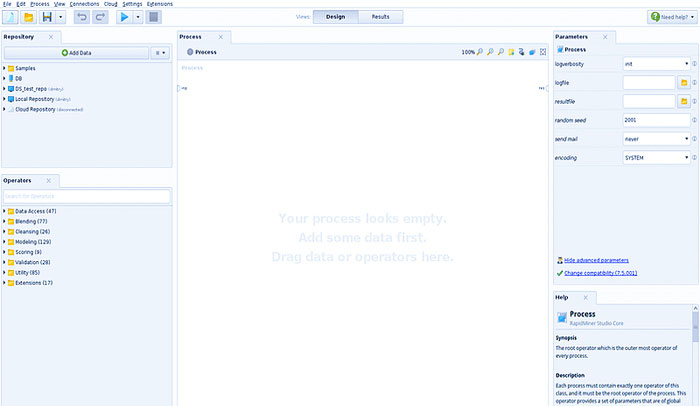
در سمت چپ صفحه می توانید یک پانل بارگذاری داده و یک پانل اپراتور را ببینید. RadpidMiner امکان دانلود داده ها از پایگاه داده یا فضای ذخیره سازی ابری (Amazon S3، Azure Blob، Dropbox) را فراهم می کند. مجموعه اپراتورها برای راحتی به دسته های زیر تقسیم می شوند
- دسترسی به داده ها (کار با فایل ها، پایگاه های داده، ذخیره سازی ابری، جریان های توییتر)
- عملگرهایی برای کار با ویژگی های مجموعه داده ها: تبدیل انواع، تاریخ ها، عملیات روی مجموعه ها و غیره.
- عملگرهای مدل سازی Mathematica: مدل های پیش بینی، مدل های تحلیل خوشه ای، مدل های بهینه سازی.
- اپراتورهای کمکی اضافی: راهانداز زیرروالهای جاوا و Groovy، ناشناسساز داده، فرستنده ایمیل و زمانبندی رویداد
ما برخی از دستههای اصلی را توضیح دادیم که هر کدام زیرمجموعهها و تغییرات عملگرهای خود را دارند. توجه به امکان افزودن اپراتورها از بازار همیشه در حال رشد RapidMiner ارزش دارد. به عنوان مثال، در میان افزونههای موجود، یک عملگر وجود دارد که به شما امکان میدهد مجموعههای داده را به سریهای زمانی تبدیل کنید.
در قسمت مرکزی صفحه می توانید یک منطقه کاری برای ایجاد فرآیندهای تبدیل داده پیدا کنید. با استفاده از کشیدن و رها کردن، داده ها را به فرآیندی که با آن کار خواهیم کرد، تبدیل داده، مدل سازی و غیره اضافه می کنیم. با مشخص کردن روابط بین داده ها و عملگرها، بردار اجرای فرآیند را دیکته می کنیم.
در مرکز پایین می توانید یک پانل با نکات پیدا کنید. بر اساس فرآیندهای ساخته شده توسط سایر کاربران، به شما توصیه می کند که کدام عملیات را بعدی تولید کنید. در سمت راست تابلویی با پارامترهای عملیات انتخاب شده و مستندات دقیق پارامترها و اصول عملیات وجود دارد.
ابتدا، اجازه دهید دادههای مربوط به تعداد درخواستهای جستجوی اوکراینی در Google مربوط به آنفولانزای رایج را بارگذاری کنیم.
رپیدماینر

داده ها تعداد درخواست ها را برای پایان هفته ها از 2005 تا 2015 نشان می دهد. هنگام وارد کردن داده ها، باید قالب تاریخ را برای ساخت صحیح نمودارهای موقت مشخص کنید. اجازه دهید خروجی بلوک داده را به نقطه خروجی نتایج فرآیند (res) متصل کنیم. پس از کلیک بر روی دکمه “شروع”، برنامه آمار کل را نشان می دهد.
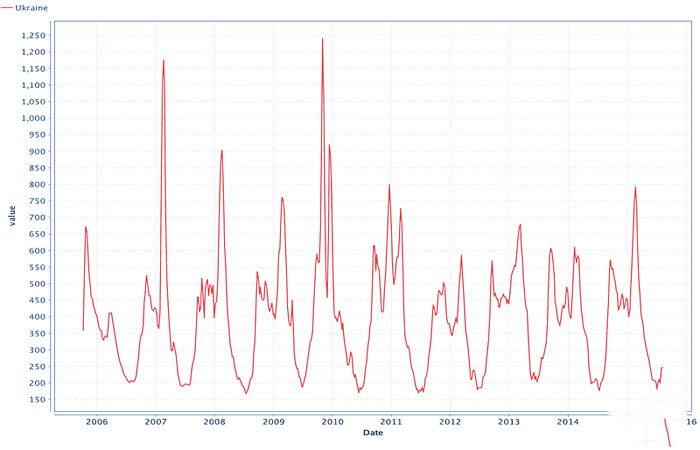
با استفاده از برگه نمودارها، اجازه دهید یک نمودار توزیع داده ایجاد کنیم (تصویر 5). نمودار تناوب ظاهری ابتلا به آنفولانزا را منعکس می کند: موج اول در پاییز شروع می شود و اوج آن در فوریه قابل مشاهده است.
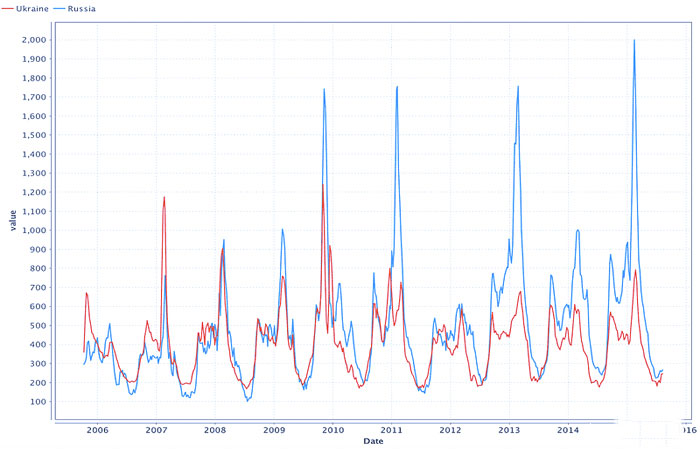
اکنون اجازه دهید دادههایی را برای روسیه در نظر بگیریم و ببینیم که آیا همان تناوب در آنها ادامه دارد یا خیر و آیا شیوع با دورههایی که در اوکراین شناسایی کردهایم مطابقت دارد یا خیر. برای انجام این کار، داده های جدید را بارگیری کنید و آنها را با داده های بارگیری شده قبلی ادغام کنید. ادغام باید در قسمت Date با کمک عملگر “Join” انجام شود.
ساخت یک مدل
اکنون اجازه دهید در مورد ساخت مدلی صحبت کنیم که تعداد موارد در اوکراین را پیش بینی می کند. قرار است ارزش سریال را برای هفته بعد بر اساس مقادیر چهار هفته قبل (تقریبا یک ماه) پیش بینی کنیم. در این مقاله از شبکه عصبی انتشار مستقیم برای پیشبینی سریهای زمانی استفاده میکنیم.
انتخاب شبکه های عصبی با سادگی انتخاب پارامترهای مدل و استفاده بیشتر از آنها توجیه می شود. برخلاف مدلهای اتورگرسیو و میانگین متحرک، شبکههای عصبی نیازی به تحلیل همبستگی سریهای زمانی ندارند.
طرح فرآیند به شما امکان می دهد مقادیر سری های زمانی را پیش بینی کنید.
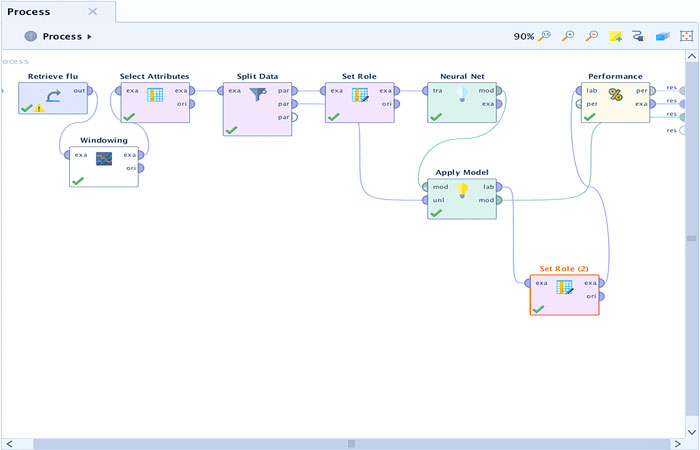
برای اینکه یک اپراتور شبکه عصبی به درستی کار کند، لازم است سری زمانی اصلی را به فرمت نمونه آموزشی تبدیل کنید. برای این کار از عملگر Windowing از بسته Series Extension استفاده کردیم. بنابراین، از ستون مقادیر، جدولی با فرمت زیر به دست آورده ایم:

سپس، با استفاده از عملگر “Select Attributes”، فیلدهای اضافی را از نمونه حذف کردیم (تاریخ مقادیر 1-4). آموزش شبکه عصبی توسط مربی نیاز به آموزش و نمونه آزمایشی دارد، بنابراین با کمک اپراتور «Split Data» BP را به نسبت 80 به 20 تقسیم کردیم.
با توجه به مستندات اپراتور «شبکه عصبی»، لازم است که ستون مقادیر پیشبینیشده در نمونه آموزشی دارای نام/نقش «برچسب» باشد که برای آن از عملگر «نقش تنظیم شده» استفاده شده است. از آنجایی که ستون «تاریخ پیشبینی» در پیشبینی شرکت نمیکند، باید نقش «شناسه» به آن اختصاص داده شود.
فروش لایسنس
باید خروجی دوم اپراتور «Split Data» و خروجی «mod» اپراتور «Neural Net» را به ورودیهای «ApplyModel» مربوطه وصل کنیم. عملگر “Apply Model” یک نمونه کنترل را به ورودی مدل آموزش دیده اعمال می کند و مقادیر پیش بینی شده و واقعی را با هم مقایسه می کند.
مرحله نهایی فرآیند ما عملگر “Performance” است که برای تعیین خطاهای نتیجه ضروری است. مقدار پیشبینیشده بهدستآمده از «مدل اعمال» با «نقش تنظیم شده (2)» نقش «پیشبینی» اختصاص یافت.
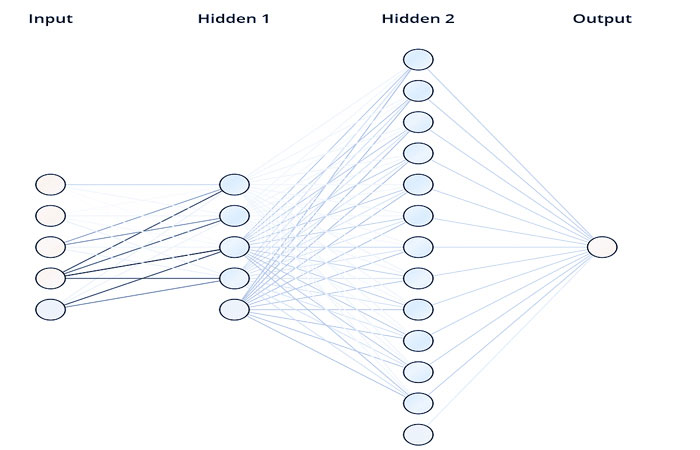
اجازه دهید پارامترهای استفاده شده توسط اپراتورهای شبکه عصبی و خطاهای محاسبات را در نظر بگیریم. با آزمایش، به معماری شبکه عصبی به تصویر کشیده شده در تصویر 8 رسیدیم. شبکه عصبی پیشروی عمیق دارای 2 لایه پنهان است: 4 نرون در اولی و 12 نورون در لایه دوم. سیگموئید به عنوان تابع فعال سازی استفاده شد. آموزش بر روی داده های ورودی نرمال شده با ضریب یادگیری 0.5 و تعداد سیکل های 1500 انجام شد.
نتایج پیش بینی
در نتیجه عملکرد مدل ما، RapidMiner سه مصنوع را ارائه می دهد:
- مدل: نمایش گرافیکی، پارامترها و بردارهای وزن آن
- نتایج خطاهای محاسبه شده
- نمونهبرداری از دادههای آزمون، تکمیل شده با ستونی از مقادیر پیشبینیشده
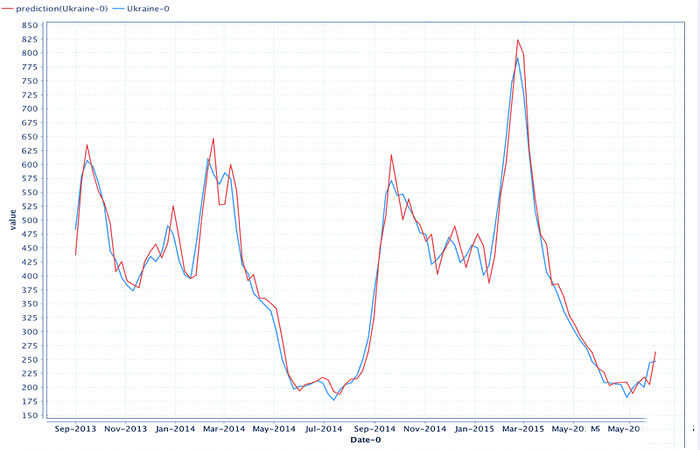
همانطور که می بینید نمودار با داده های پیش بینی شده بسیار نزدیک به داده های واقعی است. ما نتایج مدل ساخته شده را با محاسبه خطای پیشبینی با استفاده از فرمولهای زیر برآورد میکنیم:
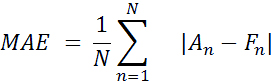
جایی که An یک مقدار واقعی و Fn یک مقدار پیش بینی شده است.
در نتیجه این را دریافت می کنیم:
MAPE = 5.47٪
MAE = 21.748
نتیجه گیری
اجرای گسترده فناوریهای یادگیری ماشینی مستلزم ایجاد ابزارهایی با درجات مختلف پیچیدگی برای کاربران نهایی بود. برنامه RapidMiner معرفی شده در مقاله آستانه ورود به مطالعه فناوری های یادگیری ماشین را کاهش می دهد.
اگر از این برنامه استفاده می کنید، نیازی به نوشتن کد در پایتون یا R ندارید. RapidMiner دائماً به شما در مورد مرحله بعدی در زنجیره آماده سازی داده ها، آموزش مدل، اعتبارسنجی و ارزیابی دقت توصیه می کند. این به شما امکان می دهد تا به طور خودکار برخی از خطاها را در فرآیند تصحیح کنید. می تواند به لحظات فردی که ممکن است قبلاً از دست داده اید کمک کند و توضیح دهد.
در حین نوشتن این مقاله به بررسی عملکرد RapidMiner پرداختیم. این بسیار گسترده است و توانایی اعمال معماری های پیچیده شبکه های عصبی و تنظیم دقیق پارامترهای آنها (انتخاب تابع فعال سازی، پیکربندی پیوندهای عصبی لایه های پنهان و غیره) را فراهم می کند.
مدل ریاضی ساخته شده در مقاله به حاشیه خطای حدود 6 درصد در داده های آزمایش رسیده است و با تغییراتی می توان از آن برای پیش بینی رشد آنفولانزا استفاده کرد. با این حال، هدف اصلی ما نشان دادن سادگی برنامه RapidMiner مورد استفاده بود.
با استفاده از RapidMiner و هر رویکرد مشابه، هر شرکتی می تواند شرایطی مشابه شیوع آنفولانزا را پیش بینی کند. اقدامات پیشگیرانه انجام شده بر اساس پیش بینی به ما امکان می دهد ریسک ها را کاهش دهیم و در نهایت سود را افزایش دهیم.
برای خرید لایسنس نرم افزار Power BI ، میتوانید از خدمات ما استفاده نموده و درخواست خود را از طریق فرم زیر ثبت نمایید.